数据库-mysql索引简介
摘要
因为各个数据库的索引机制不尽相同,在此涉及到mysql的两种索引b-tree、hash。
这里所指的所有数据库都是指mysql.
索引的本质
mysql官方文档对索引的描述:索引是帮助mysql高效获取数据的数据结构。so 索引的本质是数据结构。涉及到查找的时候肯定避不开查找算法,例如顺序查找、二分查找。随着人们对查找性能要求的越来越高就延伸出来了基于树的查找,例如二叉树的查找。当然即使是二叉树的查找也无法满足现在程序对于查找性能的要求,进而出现了基于b-tree、hash的查找。可以分析下查找的演变过程,所有的查找都是基于一定的数据结构,例如最开始顺序查找基于链表、二分查找基于有序链表、二叉树查找基于树。这种为了满足这种高效小的查询效率所衍伸出来的数据结构就是索引。
索引的选择
基于树的查找效率由树的深度决定,所以二叉树是无法满足查询速度的要求,mysql的索引主要使用 b+tree。
b-tree
b-树(由b-tree翻译过来)也就是b树,是一种路自平衡搜索树。如果我们以一个二元组来表示索引的内容的话([key,val]),key表示键值,val表示数据(地址或者主键),则b-树有以下特点。
树的度的定义:每个节点包含子树的个数。
特点
- 所有的键值分布在整个树种(包括叶子节点和非叶子节点)
- 任何key只会出现一次
- 所有的叶子节点必须在同一层次,也就是他们具有相同的深度。
- 每个节点里的关键字是有序的(一个结点中的key从左至右非递减排列),当前节点的左右两个指针指向的节点,左指针指向的节点的key小于当前节点,右指针指向的节点的key大于当前节点。
- d>=2,每个节点有n-1个
key和n个指针,d<=n<=2d。
假设b-tree的度为d,高为h,其索引个数为N。则h=logd((n+1)/2),查找一条数据的渐进复杂度为logdn。由于索引数量n和其高度h程对数关系(实际使用中d一般会大于100),所以即使是key很大,查询效率也会很快,分析可以的出b-tree查找一个最多需要h-1次磁盘io。
举个栗子一个度为1001,高度为2(不包含根节点)的b-tree可以存储超高10亿的数据,且每个节点如果使用二分查找的话,只需要三次查找就可以查询到所需的数据。
结构图
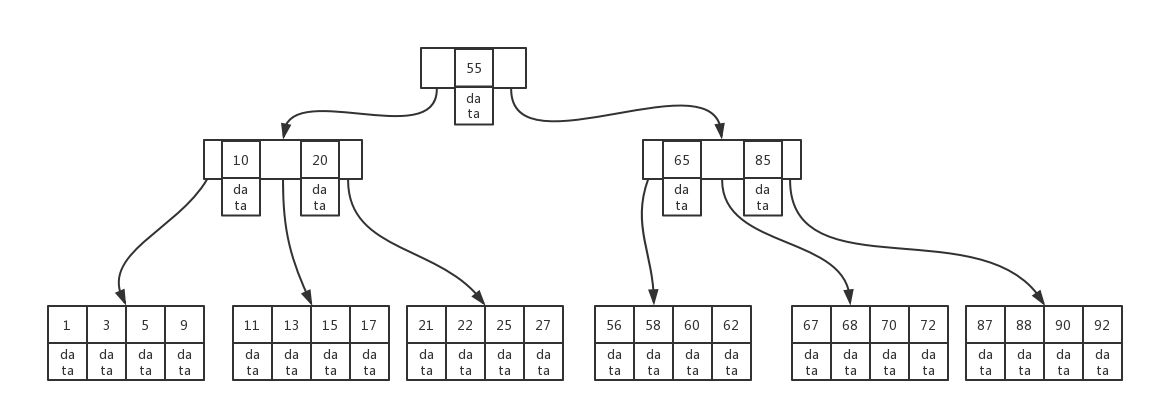
b+tree
b+tree是是b-tree的升级版,所有的data值存在叶子节点。
特点
- b+tree树只有叶子节点包含data,非叶子节点只存key与指针
- 所有的叶子节点为一个链表
结构图
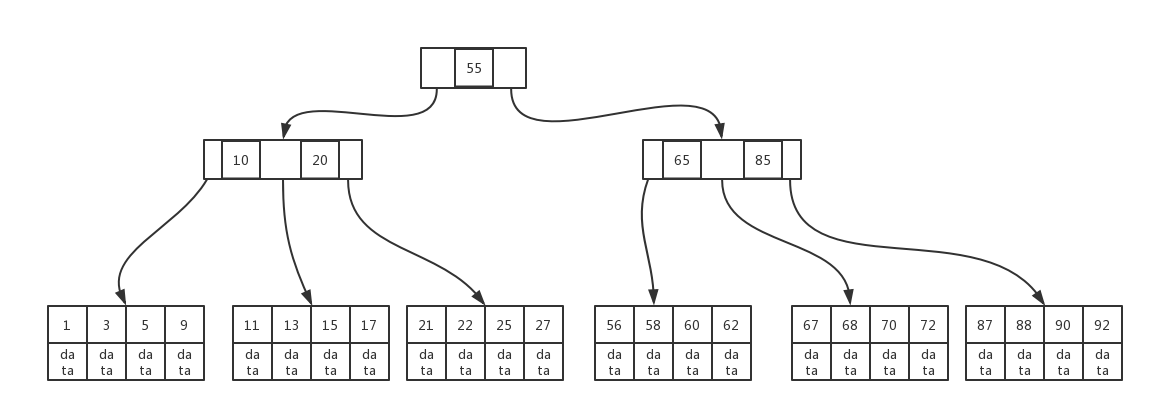
索引原理
- 聚簇索引 :索引和文件为同一个文件。
- 非聚簇索引: 索引和数据文件分开的索引。
MyISAM 和 InnoDb都使用b+tree索引结构,但是底层确实不一样的,MyISAM采用的事非聚簇索引,而innoDB采用的是聚簇索引。
MyISAM
MyISAM索引原理 : 采用的费聚簇索引 My-ISAM myi索引文件和myd数据文件分离,索引文件值保存数据记录和指针地址。叶子节点data存执指向数据记录的地址。
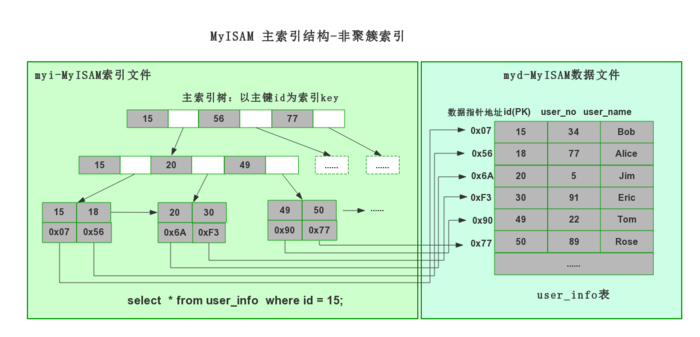
InnoDB
结构
InnoDB物理存储文件结构说明:
InnoDB以表空间Tablespace(idb文件)结构进行组织,每个Tablespace包含多个Segment段(Segment 分为为叶子节点和飞叶子节点Segment),一个Segment段包含多个Extent,一个Extent占用1M空间且包含64page,innoDB b+tree一个逻辑节点就分配一个屋里Page,一个节点一次io操作。一个page里包含d个Row行数据,行数据包
每一个索引是一个b+tree,一个节点是=一个page(16k)。数据会按照16kb切片为page并编号,标号可以通过偏移量(16k*n)找到文件存储地址。且叶子节点为双向链表,数据按主键索引聚簇索,二级索引叶子节点存储主键值,除了覆盖索引其他二级索引都通过主键查找数据。
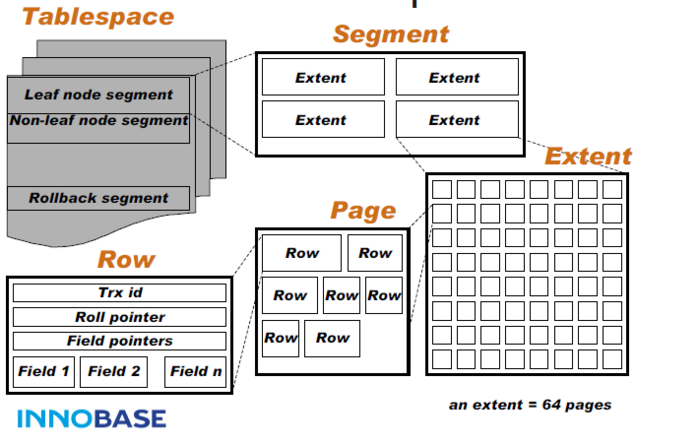
原理
InnoDB采用聚簇索引,存储于idb文件里,表数据本身就是主索引,相邻的索引临近存储。叶节点data域保存了完整的数据记录(data(除主键外所有数据)+key(主键))。也是由于这种方式InnoDB必须建指定主键,如通过没有指定主键则mysql自动选择一个可以唯一表示数据记录的列作为主键。如果这样的列不存在,mysql自动为表生成一个隐含字段(6个字节长整型)作为主键。
mysql所有的辅助索引data存储皆为主键值
结构图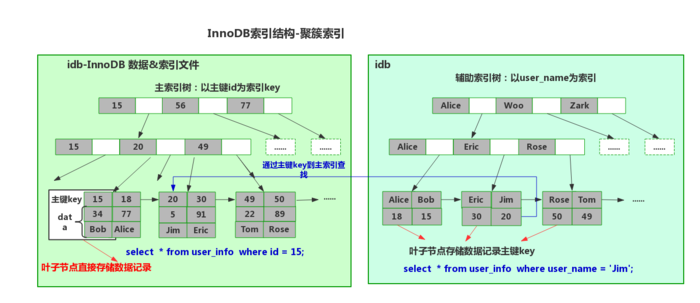
查询流程
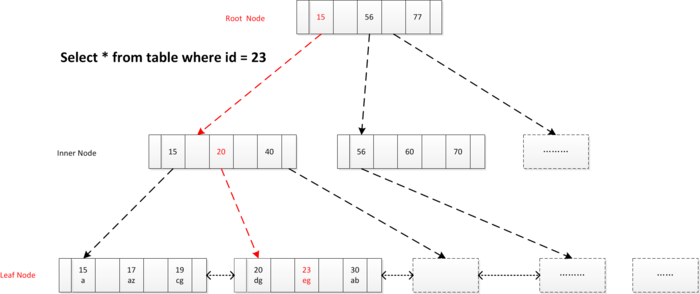
1.索引精确查找
确定定位条件, 找到根节点Page No, 根节点读到内存, 逐层向下查找, 读取叶子节点Page,通过 二分查找找到记录或未命中。(select * from user_info where id = 23)
2.索引范围查找
读取根节点至内存, 确定索引定位条件id=18, 找到满足条件第一个叶节点
, 顺序扫描所有结果, 直到终止条件满足id >=22 (select * from user_info where id >= 18 and id < 22)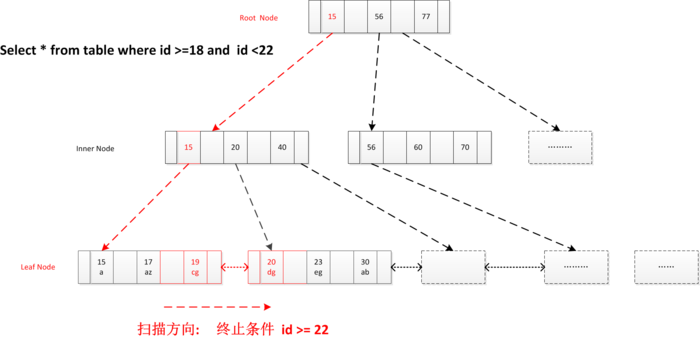
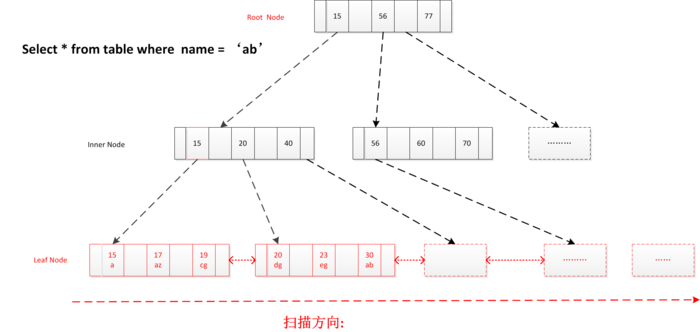
3.全表扫描
直接读取叶节点头结点, 顺序扫描, 返回符合条件记录, 到最终节点结束
(select * from user_info where name = ‘abc’)
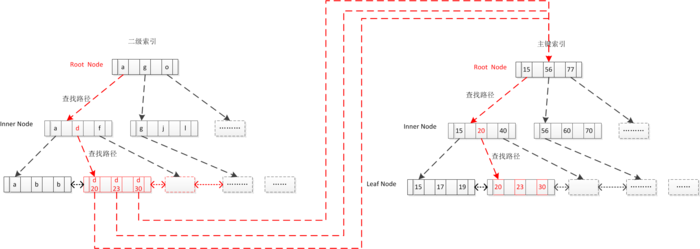
4.二级索引查找
建立索引
Create table table_x(int id primary key, varchar(64) name,key sec_index(name) )
如果执行select * from table_x where name = 'xxxx'
总结
mysql为什么选择b+tree
内存读取和存盘读取不在一个数量级,所以一般内存读取相较于与磁盘io可以忽略不计。一般来说,索引的大小是无法全部存在ram里的so衡量一个索引的优劣可以以磁盘io次数来衡量。这里就可以排除h黑大的红黑树。b-tree和b+tree一次检索最多需要查询h-1个节点,但是b+tree不存data数据,索引可以存的key更多,这样查询的节点数也就也少,磁盘io也就越少。
详解:Mysql设计利用了磁盘预读原理,将一个B+Tree节点大小设为一个页大小,在新建节点时直接申请一个页的空间,这样就能保证一个节点物理上存储在一个页里,加之计算机存储分配都是按页对齐的,这样就实现了每个Node节点只需要一次I/O操作。(一个物理Page16K)
一般一个key的大小为8b指针的大小也为8b,这样一个page可以存储(16k/16b=1000)条记录,n层数据可以存储k的n次方跳数据,一亿条数据也不过3层而已,可谓非常高效。
为什么要建立索引
如全表扫描扫描那样,我们不能保证每次查询都能在前几个page里查询到所需的数据,目标数据越往后,查询效率就越慢,如果有1亿跳数据,数据查询将会慢的恐怕。
是否索引越多越好
每一个索引都是一个树,每次插入和删除都可能破坏原有的树,当树破坏是mysql需要重新把树平衡,这会消耗资源,所以索引不宜过多。