数据库-explain
官方文档
使用explain可以分析sql的执行情况,定位慢sql的问题,从而可优化查询语句。explain的官方文档
explain的官方文档
使用方法
使用方法,在select前加上explain即可。
|
|
结果如图,会涉及到多个字段。

| 参数 | 结果 | 含义 |
|---|---|---|
| id | 1 | 第几个执行的语句 |
| select_type | SIMPLE | 查询类型) |
| table | cm_car_dealer | 表示从哪张表获取的数据 |
| type | range | 区间索引 |
| possible_keys | PRIMARY | 表示mysql可以使用哪些索引来查到这条记录 |
| key | PRIMARY | 实际使用到的索引。如果为NULL,则没有使用索引 |
| key_len | 4 | 主键是int型,所以为4.一般来说这个越小越好 |
| ref | 表示mysql可以使用哪些索引来查到这条记录 | |
| rows | 159 | 表示需要遍历多少行才能找到当前数据 |
| Extra | Using where | 执行状态说明 |
id查询的序号
表示当前查询的序号,其值为数字,表示sql执行的次序。
id相同
当id相同时,执行顺序是自上而下的。
|
|

id不同
当id不同时,id序号递增,id越大的越先被执行。
|
|

既有id相同,也有id不同的
如果既有id相同,也有id不同的。首先按照id由大到小次序执行,如果id相同则执行顺序为由上到下。
|
|

select_type
select_type表示查询的类型,主要有普通查询、联合查询、子查询和复杂查询。
1.simple: 为建单的select查询,查询中不包含子查询或者union
2.primary: 查询中包含任何复杂的子部分,最外层查询被标记为primary
3.subquert: 在select或者where列表中包含了子查询
4.derived: 在from列表中包含的子查询被标记为derived(衍生),mysql或递归执行这些子查询,把结果放在临时表里
5.union:若第二个select出现在union之后,责备标记为union;若union包含在from子句的查询中,外城select将被标记为derived
6.union result :union的结果
单独解释下第六项,如下。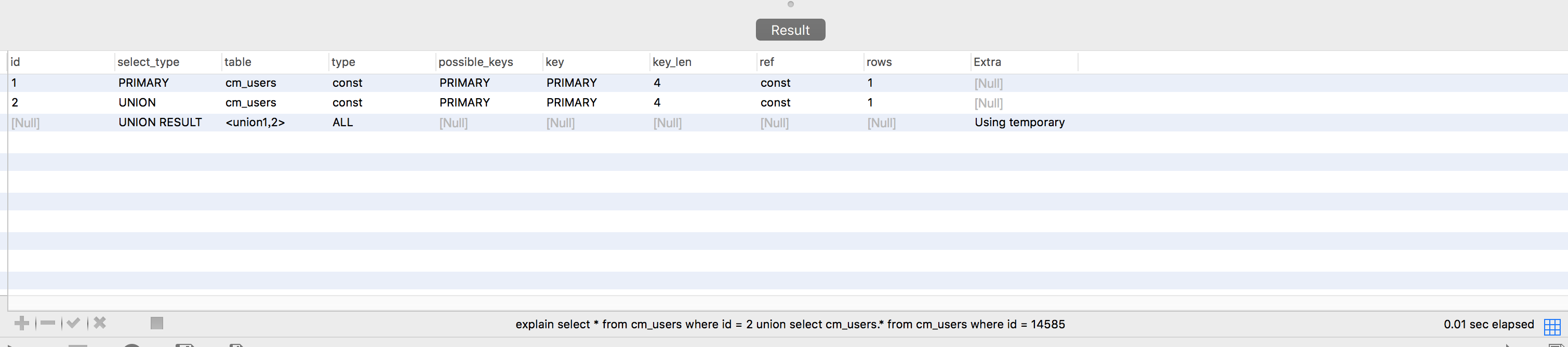
type
官方全称为type join意思为链接类型,从字面意思很容易误解为两个表的链接,其实并不是这样的。这里更应该理解为数据库引擎查找表的一种方式。《高性能mysql》称呼它为访问类型。是sql查询优化中的一个很重要的指标。
mysql5.7中type的类型达到了14种之多,这里只对常见的类型进行排序,结果有好到坏顺序为:
system > count > eq_ref > ref > fulltext >ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
好sql的标准是:至少达到range,最好达到ref。从最坏的一一开始介绍。
ALL
这既是传说的扫全表,例如 select * from cm_users where 'name' = "张三",在cm_users 里name未建立索引,因为name不是唯一的,所以即使mysql找到了名为张三的记录,也不会停下来,因为无法确定时候还有叫张三的。这样就会扫全表全量的数据,并且不是走索引的扫全表。
这种情况如果是为了展示全量的数据还好,如果是普通查询查出现了all,说明有很大优化空间。
index
通过索引扫全表,和上边比,半斤八俩,但是通过索引读取的数据有序。
range
range指的是,通过索引有范围的扫描,mysqls在找到范围的开始结束节点时,会通过索引链表扫描指定范围的数据。
ref
指的是非唯一性索引扫描,扫描当前所选择索引的全量数据,找到满足条件的所有数据,这里是所有数据,因为索引是非唯一,所以mysql需要扫描全量的索引。
例如
eq_ref
唯一性索引查找,对于每个索引,表中只有一条记录与之匹配。常见于主键或唯一索引。
|
|


const
eg:

system
当表里只有一条数据,或者子查询和父查询条件重复时会发生,一般不会出现。
eg:

possible_keys
查询涉及到的到的字段上如果有索引,则该索引将会被列出来,但不一定被查询实际使用。
key
实际使用的索引,如果没有使用索引则为NULL。
key_len
表示索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。
ref
显示索引的哪一列被使用了,有时候会是一个常量:表示哪些列或常量被用于用于查找索引列上的值

row
表示此次查询需要读取的行数。
extra
Using filesort
如果使用非索引列进行排序,则extra会展示Using filesort
eg:
|
|

Using temporary
如果mysql 使用临时表保存中间结果,
eg:

Using index
表次此次查询使用了覆盖索引,没有直接访问表的数据行,效率高。如果同时出现了 using where,表明索引用来执行索引键值的查找。如果没有出现using where 表明索引只是用来读取数据。
覆盖索引:当前查询的数据在索引内都存在,则不需要访问数据表即可获取数据。如果要使用覆盖索引不可使用
select *,如果给所字段建立索引则会降低数据库写入更新速度。
Using where
使用了where过滤
Using join buffer
使用了链接缓存
Impossible WHERE
where永远为不可成立的条件时出现
distinct
优化distinct操作,在找到第一个匹配的数据时,停止对同样的值寻找。