php的数组依赖于hashtable实现的。
Times33的算法很简单,就是不断的乘33,下边是times33算法:
Times33(hash)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16
| <?php function myHash($str) { $hash = 5381; $s = md5($str); $seed = 5; $len = 32; for ($i = 0; $i < $len; $i++) { $hash = ($hash << $seed) + $hash + ord($s{$i}); } return $hash & 0x7FFFFFFF; }
|
其中<< 表示左移,每次左移表示x2例如:
1 2 3 4
| <?php $num = 2; echo $num << 2;
|
所以($hash << $seed)表示 $hash * 32 ,同时加上$hash,也就表示 $hash * 33了。ord()函数返回字符串的首个字符的 ASCII 值。
最后$hash & 0x7FFFFFFF 表示与整形的最大值与操作(0x7FFFF111FFF二进制为1111111111111111111111111111),
这个与操作会截取超过整形二进制部分,所以times33计算出来的值不会超过整形的最大值。
为什么要用hashtable实现php数组?
因为散列表是根据关键建码值直接进项访问的数据结构。在key和value之间有一个映射函数,可以根据key直接索引到对应的value值,它并
不会使用一般的对比操作,而是直接使用内存的起始位置和偏移位置进行寻址,所以会比正常的寻址要快。
散列表结构
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
| struct _zend_array { zend_refcounted_h gc; union { struct { ZEND_ENDIAN_LOHI_4( zend_uchar flags, zend_uchar nApplyCount, zend_uchar nIteratorsCount, zend_uchar reserve) } v; uint32_t flags; } u; uint32_t nTableMask; Bucket *arData; uint32_t nNumUsed; uint32_t nNumOfElements; uint32_t nTableSize; uint32_t nInternalPointer; zend_long nNextFreeElement; dtor_func_t pDestructor; };
|
主要字段介绍:
- gc 引用次数,垃圾回收时会用到。
- union u 就不介绍了。
- arData 存储元素的数组,内存是连续的,arData指向第一个元素。
- nTableMask nTableSize的负数。
- nTableSize 数组长度,为2的n此房。
- nNumUsed 当前使用的Bucket数。
- nNumOfElements 当前所有的Bucket数。
- nNextFreeElement 下一个被使用的Bucket($a[] = ‘’)
- pDestructor 删除某个元素是会使用
Bucket结构
1 2 3 4 5
| typedef struct _Bucket { zval val; zend_ulong h; zend_string *key; } Bucket;
|
- h hash出来的值(times33)
- *key 存储元素的key
- val 具体值,是个zval
如何实现
php中实现散列表实现主要使用存储元素数组和 映射函数(也可以称作散列函数)和映射表
举个具体的栗子:
如果我们要在php代码中声明一个数组会发生什么?下边分析下php是如何实现数组的。
1 2 3 4 5 6
| <?php $arr= [ 'a' => '111', 'b' => '222', 'c' => 'ccc' ];
|
- 首先肯定是初始化。
- 接下来将每个元素对应的值依照顺序拷贝到 Bucket里。
- 然后利用映射函数对求值,根据算出来的值将其对应的bucket的地址写到该值对应的映射这表里。
具体操作如下图:
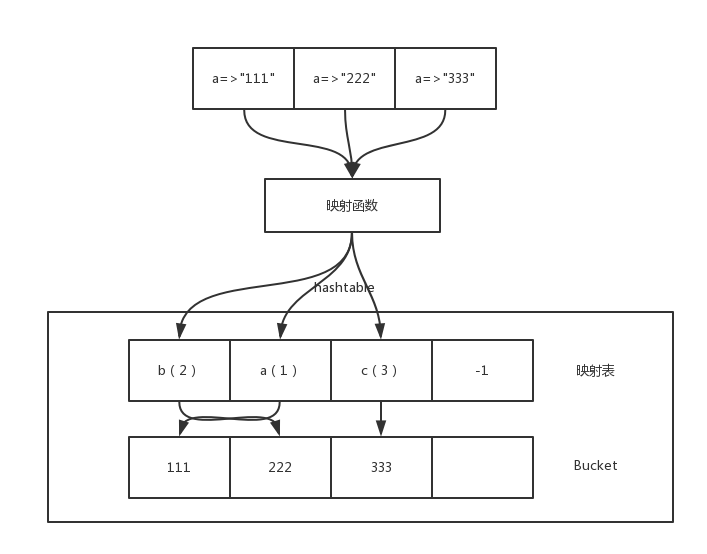
当然我们这里的映射是理想映射,因为在映射的计算过程中可能存在冲突,后续会介绍映射函数,以及如何解映射函数计算后的冲突。
初始化
1 2 3 4 5 6 7 8 9 10 11 12 13 14
| ZEND_API void ZEND_FASTCALL _zend_hash_init(HashTable *ht, uint32_t nSize, dtor_func_t pDestructor, zend_bool persistent ZEND_FILE_LINE_DC) { GC_REFCOUNT(ht) = 1; GC_TYPE_INFO(ht) = IS_ARRAY; ht->u.flags = (persistent ? HASH_FLAG_PERSISTENT : 0) | HASH_FLAG_APPLY_PROTECTION | HASH_FLAG_STATIC_KEYS; ht->nTableMask = HT_MIN_MASK; HT_SET_DATA_ADDR(ht, &uninitialized_bucket); ht->nNumUsed = 0; ht->nNumOfElements = 0; ht->nInternalPointer = HT_INVALID_IDX; ht->nNextFreeElement = 0; ht->pDestructor = pDestructor; ht->nTableSize = zend_hash_check_size(nSize); }
|
初始化的时候主要是对hashtable中各个成员的进行初始化设置,而且在这个时候不会给arData分配内存,只有在开始插入数据的时候才会
为arData分配内存。
映射函数
映射函数其实就是一次hash操作和和一次|操作.
hash操作就是上边锁提到得到times33操作,|操作是计算出来的hash值与nTableSize进行计算。
1
| nIndex = ket->h | nTableMask;
|
因为nTableMask是nTableSize的负数,所以计算出来的nIndex值区间应该为[-1,nTableMask]。
此处待补充 为什么会在[-1, nTableMask] 区间内。
写入数据
在初始化的时候并不会对arData分配内存,只有在写入的时候才会真正分配内存
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| static void zend_always_inline zend_hash_real_init_ex(HashTable *ht, int packed) { HT_ASSERT(GC_REFCOUNT(ht) == 1); ZEND_ASSERT(!((ht)->u.flags & HASH_FLAG_INITIALIZED)); if (packed) { HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_PERSISTENT)); (ht)->u.flags |= HASH_FLAG_INITIALIZED | HASH_FLAG_PACKED; HT_HASH_RESET_PACKED(ht); } else { (ht)->nTableMask = -(ht)->nTableSize; HT_SET_DATA_ADDR(ht, pemalloc(HT_SIZE(ht), (ht)->u.flags & HASH_FLAG_PERSISTENT)); (ht)->u.flags |= HASH_FLAG_INITIALIZED; if (EXPECTED(ht->nTableMask == -8)) { Bucket *arData = ht->arData; HT_HASH_EX(arData, -8) = -1; HT_HASH_EX(arData, -7) = -1; HT_HASH_EX(arData, -6) = -1; HT_HASH_EX(arData, -5) = -1; HT_HASH_EX(arData, -4) = -1; HT_HASH_EX(arData, -3) = -1; HT_HASH_EX(arData, -2) = -1; HT_HASH_EX(arData, -1) = -1; } else { HT_HASH_RESET(ht); } } }
|
分配具体的内存
1 2
| #define HT_SIZE_EX(nTableSize, nTableMask) \ (HT_DATA_SIZE((nTableSize)) + HT_HASH_SIZE((nTableMask)))
|
1 2 3 4 5
| #define HT_HASH_SIZE(nTableMask) \ (((size_t)(uint32_t)-(int32_t)(nTableMask)) * sizeof(uint32_t)) #define HT_DATA_SIZE(nTableSize) \ ((size_t)(nTableSize) * sizeof(Bucket))
|
可以看到在分配具体分配内存的时候会分配 nTableSize(Bucket+uint32_t)大小的内存。
讲道理只需要分配nTableSizeBucket大小内存就可以了,为什么会多余出来 nTableSizeuint32_t内存呢?
因为nTableSizeuint32_t就是映射表所占内存大小。所以说Bucket会和映射表一次申请内存。
写完成写入操作以后会将*arData 指向第一个Bucket。
具体在内存里的结果如图所示:
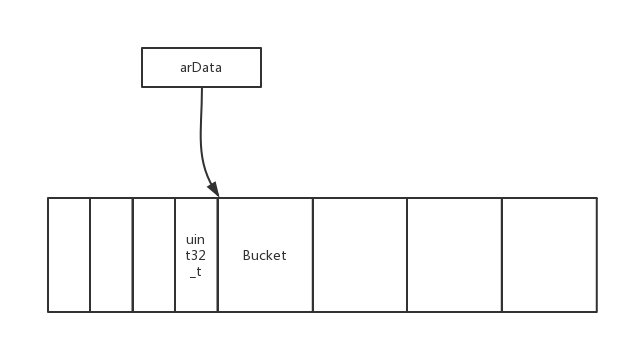
映射表在初始化的时候所有值都是-1,只有在被赋值时候会写入对应Bucket所在链表的偏移量。;
ht->arData 指向第一个Bucket的位置,在赋值的时候会按照列表顺序,将值写入Bucket的value里,然后会根据
映射函数算出值当做偏移量找到对应映射表的元素,然后将当前Bucket写入此元素。
ps nTableSize 为2的次方倍。
冲突
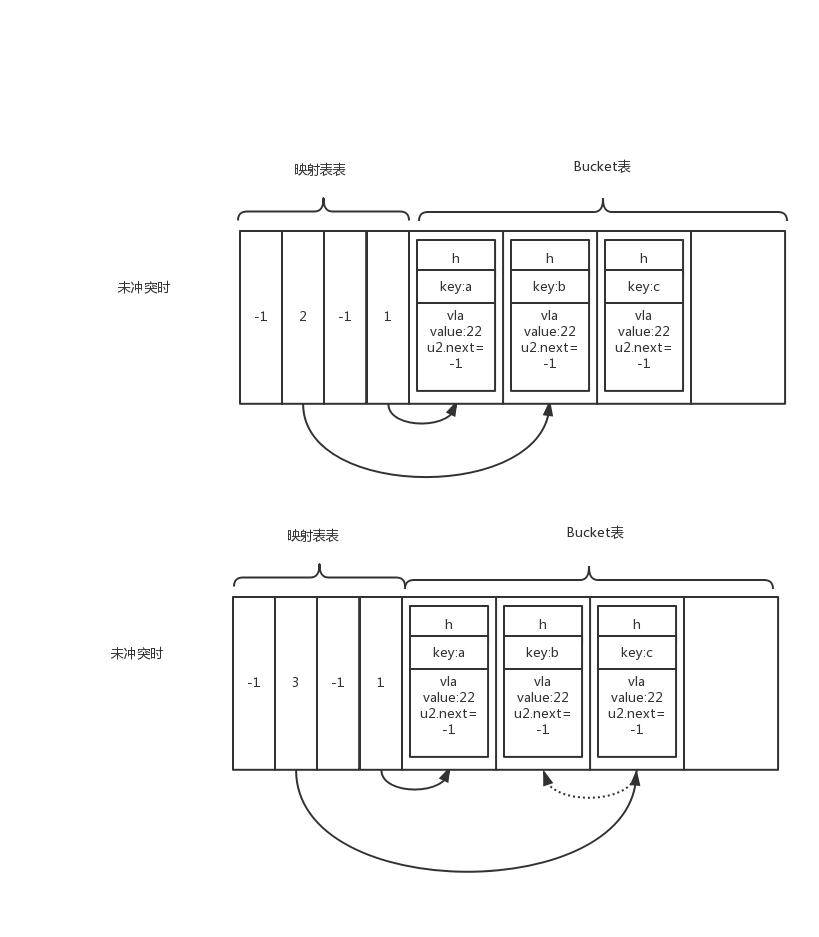
如果nIndex = ket->h | nTableMask 算出来的值冲突了怎么办? 首先映射表的每个元素不是链表,所以导致无法存储多个元素。
在php中是这样处理冲突的:
首先映射表的所有元素初始化值为 -1 ,当前
如果用冲突会将新算出来的值对应的Bucket覆盖原来旧的Bucket,然后将旧的Bucket迁移到新的Bucket,
并将旧的Bucket的u2.next(默认为-1) 指向新Bucket。
如图
查找
php再查找一个数组元素是,首先会根据其key 获取到计算后hash值’ket->h’,然后根据映射函数算出当前元素在映射表中的偏移量,利用当前位置+偏移量找到映射表的元素,再根据其内的偏量找到对应Bucket链表的首个元素位置,最后遍历该链表核对key值,找到对应的值。
具体实现函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25
| static zend_always_inline Bucket *zend_hash_find_bucket(const HashTable *ht, zend_string *key) { zend_ulong h; uint32_t nIndex; uint32_t idx; Bucket *p, *arData; h = zend_string_hash_val(key); arData = ht->arData; nIndex = h | ht->nTableMask; idx = HT_HASH_EX(arData, nIndex); while (EXPECTED(idx != HT_INVALID_IDX)) { p = HT_HASH_TO_BUCKET_EX(arData, idx); if (EXPECTED(p->key == key)) { return p; } else if (EXPECTED(p->h == h) && EXPECTED(p->key) && EXPECTED(ZSTR_LEN(p->key) == ZSTR_LEN(key)) && EXPECTED(memcmp(ZSTR_VAL(p->key), ZSTR_VAL(key), ZSTR_LEN(key)) == 0)) { return p; } idx = Z_NEXT(p->val); } return NULL; }
|
扩容
数组的容量在初始化的时候已经确定了大小,就是nTableSize。当然映射函数也是根据 nTableMask 来计算的。
所以我们扩容时候必须重新计算索引,也就是映射表里的值。
具体扩容规则:
首先当需要扩容时,会计算当前Bucket链表里删除元素数量占总表元素数量的比例,如果没有超过阈值则申请分配一个原来数组大小两倍的新素组,把元素复制到新数组上,然后重新建立索引。
阈值判断:
1
| ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements >> 5
|
处理过程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28
| static void ZEND_FASTCALL zend_hash_do_resize(HashTable *ht) { IS_CONSISTENT(ht); HT_ASSERT(GC_REFCOUNT(ht) == 1); if (ht->nNumUsed > ht->nNumOfElements + (ht->nNumOfElements >> 5)) { HANDLE_BLOCK_INTERRUPTIONS(); zend_hash_rehash(ht); HANDLE_UNBLOCK_INTERRUPTIONS(); } else if (ht->nTableSize < HT_MAX_SIZE) { void *new_data, *old_data = HT_GET_DATA_ADDR(ht); uint32_t nSize = ht->nTableSize + ht->nTableSize; Bucket *old_buckets = ht->arData; HANDLE_BLOCK_INTERRUPTIONS(); new_data = pemalloc(HT_SIZE_EX(nSize, -nSize), ht->u.flags & HASH_FLAG_PERSISTENT); ht->nTableSize = nSize; ht->nTableMask = -ht->nTableSize; HT_SET_DATA_ADDR(ht, new_data); memcpy(ht->arData, old_buckets, sizeof(Bucket) * ht->nNumUsed); pefree(old_data, ht->u.flags & HASH_FLAG_PERSISTENT); zend_hash_rehash(ht); HANDLE_UNBLOCK_INTERRUPTIONS(); } else { zend_error_noreturn(E_ERROR, "Possible integer overflow in memory allocation (%zu * %zu + %zu)", ht->nTableSize * 2, sizeof(Bucket) + sizeof(uint32_t), sizeof(Bucket)); } }
|
在处理的过程中还会把已经删除的Bucket给删除。
具体的操作在zend_hash.c文件里。
如果超过阈值,则会把已经删除Bucket移除,然后把又有后边的元素往前移动,补上空缺的Bucket,当然索引也会重建。
参考